背景
開発者として、間違いなくローカルで環境を立ち上げて開発するのは一番楽です。
ただし、localhost で開発するには限界がある。
- localhost と言うドメインはブラウザとシステムに特別な扱いされている
- もちろん hosts ファイルを更新したらある程度避ける問題ですが、メンテは面倒です。
- SSL 証明書を発行出来ない
- 簡単に外部からアクセス出来ない
- 同じ LAN にあるデバイスでも簡単にアクセス出来ない
そういう時リバース SSH トンネルと言う裏技を使えばクリアできる!
ゴール
- ローカルマシンで走っているサーバーを任意のドメイン名でアクセスできるように
- SSL 接続が可能
- SSL 証明書はLet’s Encryptで自動的に更新される
- モバイル端末の設定(証明書、host files など)を変えず、自然にアクセスできる
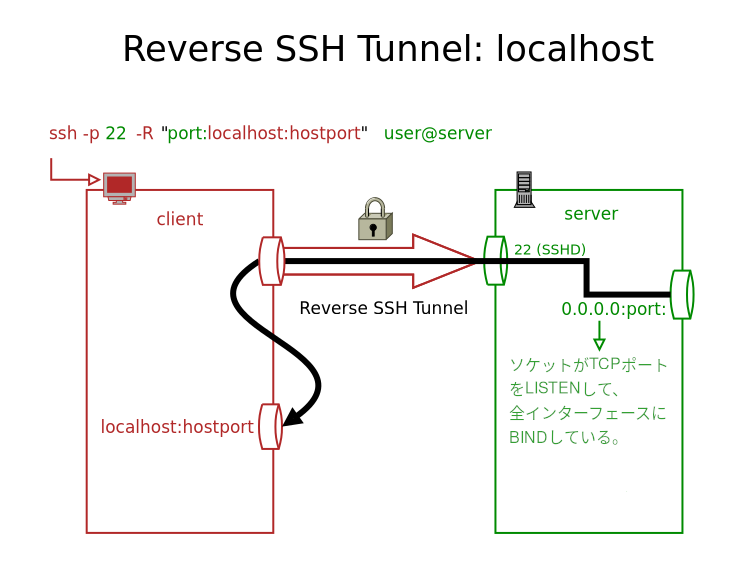
リバース SSH トンネルとは?
基本的に、SSH トンネルの中に、逆方向の SSH トンネルを開くと言う事です。
クライアント(=ローカルマシン)がサーバーに接続して、更にサーバーのポートをクライアントに繋げるトンネルを作成する。
クライアントとサーバーの間にファイアウォールがあったとしても、サーバーと通してクライアントにアクセスできる。
オンラインサービス・ツール
待て待て待て、そういうのはすでに存在しているでしょう?
はい、おそらく一番人気のあるサービスは ngrok です。
ngrok は間違いなくとても便利で強力なツールです。
ngrok なら、カスタムドメインのため、有料プランが必要です。
ただし、最近の値上げの影響で(月$8から$20に)、諦めました。

じゃあ、他になにかあるのではないですか?実はたくさんあります。無料や低コストのオプションはいくつかがありますが、だいたい、自由にドメイン名を選べないまたは不安定であまり使えないサービスが多いです。
ソリューションにたどり着いた
SSHトンネルサーバー
これだ!
自分のサーバーにこのコードをデプロイすれば、
- 自分の好みのドメイン・サブドメインを使用できる。
- 自動的にLet'sEncryptでSSL証明証を発行してもらえる
- ワイルドカード証明書で運用したいため、DNS バリデーションが必要
- Route53プロバイダがあるから、インフラと簡単に連携できる
- 特別なクライアントをインストールする必要がない
- SSHのクライアントがあれば十分
- 欲しければ、SSHの公開鍵でアクセス制限できる
- 好きなサーバーでデプロイできるので、レイテンシに気にする必要がない
このトンネルサーバーはSSHサーバーですが、トンネル専用になっている、自分のポートでListenしている。
その他の材料
- Docker
- コンテナで走らせるのは一番楽
- AWS
Dockerコンテナの準備
まずはEC2インスタンスにログインする。
ユーザーのホームで上記プロジェクトのコードをクローンする
git clone https://github.com/antoniomika/sish.git
これで sish フォルダができる。
~]$ ls -l
total 0
drwxrwxr-x 11 ec2-user ec2-user 317 Jun 16 07:20 sish
そのフォルダの中に入って、一旦新しいブランチで変更を行いましょう(野蛮人ではないから)
sish]$ git switch -c localconfig
そして、変えたいファイルは2つがある:
deploy/docker-compose.ymldeploy/le-config.yml
deploy/docker-compose.yml
デフォルト状態はこんな感じ
version: '3.7'
services:
letsencrypt:
image: adferrand/dnsrobocert:latest
container_name: letsencrypt-dns
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./letsencrypt:/etc/letsencrypt
- ./le-config.yml:/etc/dnsrobocert/config.yml
restart: always
sish:
image: antoniomika/sish:latest
container_name: sish
depends_on:
- letsencrypt
volumes:
- ./letsencrypt:/etc/letsencrypt
- ./pubkeys:/pubkeys
- ./keys:/keys
- ./ssl:/ssl
command: |
--ssh-address=:22
--http-address=:80
--https-address=:443
--https=true
--https-certificate-directory=/ssl
--authentication-keys-directory=/pubkeys
--private-keys-directory=/keys
--bind-random-ports=false
--bind-random-subdomains=false
--domain=ssi.sh
network_mode: host
restart: always
自分の好みに変更しないといけない!
- 特定ポート番号(
2222)で運用する。そうすれば、SSHとかぶらない - ドメイン名を変える。仮に私の会社が
totemohoge.comのドメイン名を使ったら、サブドメインを自由に取れば困るだろう。よって、サブサブドメインでやる。このサーバーはtunnel.totemohoge.comになる。ユーザーが作成するトンネルはそのサブドメインの直下になる。例えばnasu.tunnel.totemohoge.com,kyuuri.tunnel.totemohoge.comなどなど - デフォルトタイムアウトは5秒でアップロードの時ちょっと厳しいと思うので、60秒まで上げる
パラメターはすべてcommandあたりで調整できる。詳細が必要だったら、プロジェクトのCLI Flagsセクションに参考してください。
するとdocker-compose.ymlはこうなる。
version: '3.7'
services:
letsencrypt:
image: adferrand/dnsrobocert:latest
container_name: letsencrypt-dns
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./letsencrypt:/etc/letsencrypt
- ./le-config.yml:/etc/dnsrobocert/config.yml
restart: always
sish:
image: antoniomika/sish:latest
container_name: sish
depends_on:
- letsencrypt
volumes:
- ./letsencrypt:/etc/letsencrypt
- ./pubkeys:/pubkeys
- ./keys:/keys
- ./ssl:/ssl
command: |
--ssh-address=:2222
--http-address=:80
--https-address=:443
--https=true
--https-certificate-directory=/ssl
--authentication-keys-directory=/pubkeys
--private-keys-directory=/keys
--bind-random-ports=false
--bind-random-subdomains=false
--domain=tunnel.totemohoge.com
--idle-connection-timeout 60s
--authentication=true
network_mode: host
restart: always
deploy/le-config.yml
このファイルを使って、自動的にLet'sEncryptで証明書を発行してもらうようになる。
Let'sEncrypt で自動化するのはかなり便利で、とてもメンテしやすい。
ただし、ワイルドカード証明書を発行するため、DNS バリデーションをしないといけない。通常のHTTPバリデーションはドメイン毎に証明書を一つ発行する必要があって、かなり面倒で大変。
ワイルドカードだったら、一つで結構です。設定はちょっと大変ですけれど。
さて、やっちゃいましょう
デフォルトは以下の通りです。
acme:
email_account: AUTH_EMAIL
certificates:
- autorestart:
- containers:
- sish
domains:
- ssi.sh
- '*.ssi.sh'
name: ssi.sh
profile: cloudflare
profiles:
- name: cloudflare
provider: cloudflare
provider_options:
auth_token: AUTH_TOKEN
auth_username: AUTH_EMAIL
まずはメールアカウントを書かないといけない。LetsEncrypt から知らせが来るので、ちゃんと存在しているアドレスを使ってください(インフラ部のメーリングリストなど)。
次は証明書のドメイン一覧です。今回はトンネルサーバーのドメイン名とそのワイルドカードサブドメインが欲しいので、
tunnel.totemohoge.com*.tunnel.totemohoge.com
になる。
name 属性は管理用の名前なので、分かりやすくするため、メインドメイン名にする
最後にプロファイル(=プロバイダー)の設定です。あれはプロバイダー毎設定は微妙に変わるので、Route53意外だったら、正しいパラメターを調べてください。
Route53の場合は、プロバイダー名は route53 で、
auth_access_keyauth_access_secretprivate_zonefalseで固定(公開するから)zone_idプロバイダーが変更できるDNSゾーンのID(セキュリティのため、専用ゾーンで運用する)
AWS の IAM で専用ユーザーを作って auth_access_key と auth_access_secret を発行して、取得できる。
AWSの設定
Route53 でホストゾーン作成して、一覧画面に戻れば、こんな感じです。
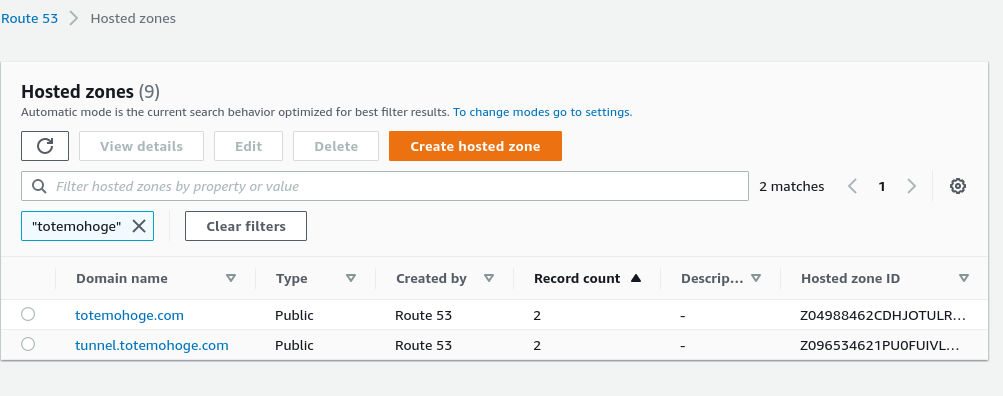
上記の zone_idは一番右のカラムの値です。ホストゾーンの詳細画面からでも取れる。
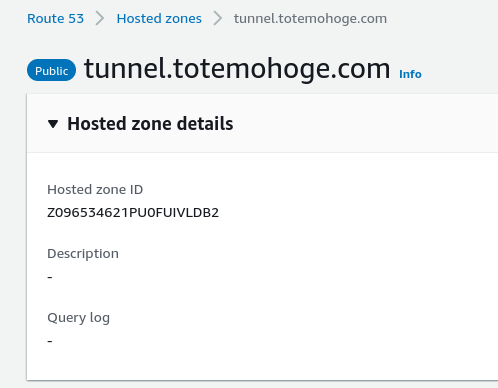
まずはEC2インスタンスへのDNSレコードを登録しないといけない。
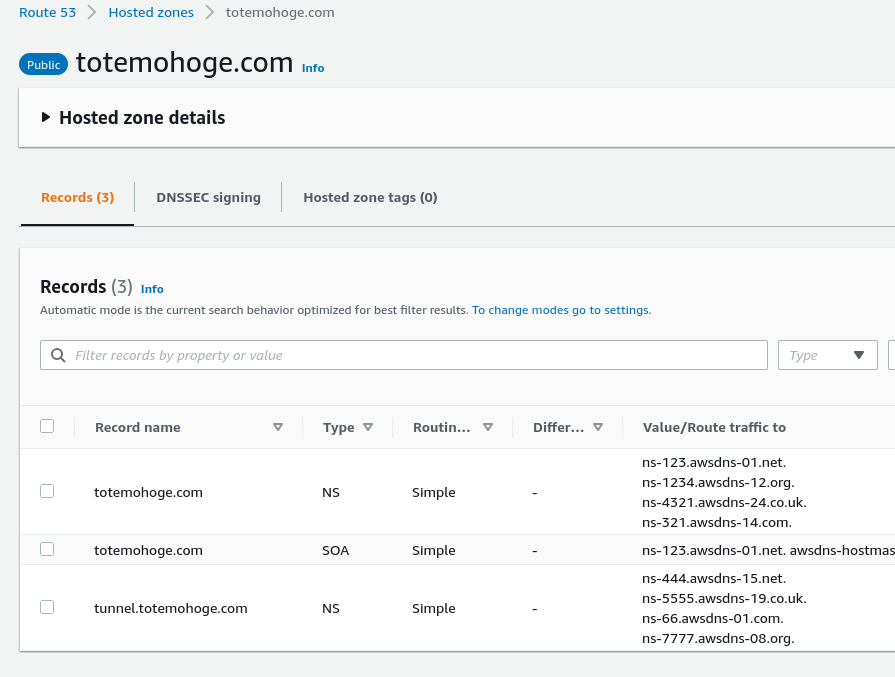
tunnel.totemohoge.com ゾーンのなかでゾーンのトップレベルのAレコードを作り、EC2インスタンスのエラスティックIPを登録する。

そして、メインゾーンに参考レコードを作らないといけない。
tunnel.totemohoge.comのNSレコードを作って、ゾーン詳細画面からネームスペースサーバーをコピペする。
そして、IAM ユーザーを作成しましょう。APIのみのユーザー(Webコンソールアクセス不要)で、ポリシーはたった一つでいいです。 <ZONE_ID> だけを書き直してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"route53:ListHostedZones",
"route53:GetChange",
"route53:GetHostedZone",
"route53:ListResourceRecordSets"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"route53:ChangeResourceRecordSets"
],
"Resource": [
"arn:aws:route53:::hostedzone/<ZONE_ID>"
]
}
]
}
このポリシーのおかげでユーザーがこの特定ゾーンのレコードを自由に作成、編集、削除できる。
作成したユーザーのキーをメモって、 deploy/le-deploy.yml ファイルに貼ってください。
acme:
email_account: naoto.date@totemohoge.com
certificates:
- autorestart:
- containers:
- sish
domains:
- tunnel.totemohoge.com
- '*.tunnel.totemohoge.com'
name: tunnel.totemohoge.com
profile: route53
profiles:
- name: route53
provider: route53
provider_options:
auth_token: <AUTH_ACCESS_KEY>
auth_username: <AUTH_ACCESS_SECRET>
private_zone: false
zone_id: Z096534621PU0FUIVLDB2
そして、リンクをつくらなければならない:
sish]$ sudo ln -s /etc/letsencrypt/live/<ドメイン名>/fullchain.pem deploy/ssl/<ドメイン名>.crt
sish]$ sudo ln -s /etc/letsencrypt/live/<ドメイン名>/privkey.pem deploy/ssl/<ドメイン名>.key
ドメイン名は証明書の第一ドメイン名となるので、上記の設定だったら、 tunnel.totemohoge.com になるはずです。
準備が出来た
では実行する時です!
docker compose で管理されているので、かなり使いやすいです。
初期化の際に様子を見ていた方が良さそうです
deploy]$ docker-compose up
一番重要はLet’sEncryptとの連携です。最初はちょっと時間がかかることがあるので、心配しないで、結果を待ってください。
エラーが起きたら、まぁ・・・頑張ってくださいとしか言えない!エラーメッセージは結構丁寧で、原因が楽に特定できる。
特に問題がなければ、おめでとうございます。
Ctrl+Cで終了して、もう一度バックグランドで実行してください。
deploy]$ docker-compose up -d
これでサーバーが自動的に走るし、 letsencrypt コンテナのおかげで自動的に証明証を更新する。 restart は always に設定されているので、インスタンスを停止し再起動すれば、コンテナも自動的に立ち上がる。
公開鍵登録
ユーザーのアクセスを制限するために公開鍵サーバーに登録する必要がある。
だれでも勝手にSSHトンネルを登録できると困る!
やり方は非常に簡単です。
クライアントマシンの公開鍵を ~/sish/deploy/pubkeysにコピーすれば完了です。
基本的に通常のSSHのauthorized_keysファイル形式です。
認証なしで運用
deploy/docker-compose.yml ファイルを更新する必要がある。
--authentication=true
を
--authentication=false
にするだけで、公開鍵チェックをスキップできる。
またはパスワード認証も対応です。個人的に好きではないが・・・
では使ってみよう!
自分のマシン簡単なWebサーバー(例:ポート8080)を起動してから、次のコマンドを実行する
~]$ ssh -p <トンネルサーバーポート> <サブドメイン名>:80:localhost:<ローカルサーバーポート> <トンネルサーバー名>
今回の設定によると下記のようなコマンドです
~]$ ssh -p 2222 datenaoto:80:localhost:8080 tunnel.totemohoge.com
※ SSHクライアントのバージョンによって、エラーが発生する場合がある。
sign_and_send_pubkey: no mutual signature supported
その時、そのドメイン用のSSH config (通常 ~/.ssh/config)に下記の行を追加してください
Host tunnel.totemohoge.com
PubkeyAcceptedKeyTypes=+ssh-rsa
成功したらこういうメッセージが表示される:
~]$ ssh -p 2222 datenaoto:80:localhost:8080 tunnel.totemohoge.com
Press Ctrl-C to close the session.
Starting SSH Forwarding service for http:8080. Forwarded connections can be accessed via the following methods:
HTTP: http://datenaoto.tunnel.totemohoge.com
HTTPS: https://datenaoto.tunnel.totemohoge.com
ここまでたどり着いたら、どんなブラウザーでも開ける。
Ctrl+Cでトンネルを閉じれば、外部からアクセスできなくなる。
かなり便利なツールです!
最後に
sish はもっと色々できるアプリケーションです。HTTP・HTTPSのトンネルだけではなく、どんな TCP ポートも対応できる。一つのドメインを管理するだけではなく、どんなドメインでも使えるようにもできる。本当に素晴らしいツールです。詳しくは Github ページに参考してください。
今のところは数ヶ月続けて使っていて、特に問題がなかったです。
ただ、そのトンネルの存在を忘れないでください。トンネルサーバーもタイムアウトがあるので、自分に合わせたユースケースのタイムアウトを設定してください。
sishプロジェクトが役に立てたら、開発者にビール一杯奢っていいと思います。🍺
株式会社フォトラクションでは一緒に働く仲間を募集しています