はじめに
こんにちは、エンジニアの酒井です。
以前、チームで頻繁に使用する関数やメソッドを共通ライブラリとして開発効率を向上させる取り組みを行い、ライブラリのドキュメントはS3とCloudFrontを用いた構成で配信することにしました。
その際、今後も同じような静的コンテンツの配信をするときにすぐにこの構成を再現できるようCloudFormationでインフラリソースをコード化しました。
今回はその際のテンプレートの内容を記述したいと思います。
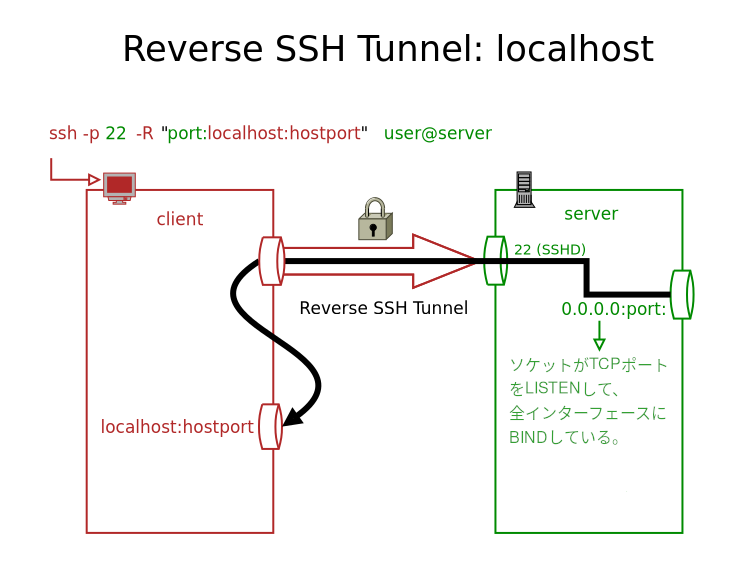
構成
レスポンス速度の向上のため、S3だけではなく、CloudFrontを間に設置し、エッジロケーション経由でコンテンツを配信する。
- CloudFrontのディストリビューションでS3バケットをオリジンに設定し、S3バケットに保存したHTMLファイルをCloudFrontを通して配信する。
- ディストリビューションにOAI(Origin Access Identity)を設定して、S3エンドポイントに直接アクセスできないようにする。
- このときS3のバケットポリシーでOAIのみアクセスを許可するよう設定する
- 参考: オリジンアクセスアイデンティティ (OAI) を使用して Amazon S3 コンテンツへのアクセスを制限する

方法
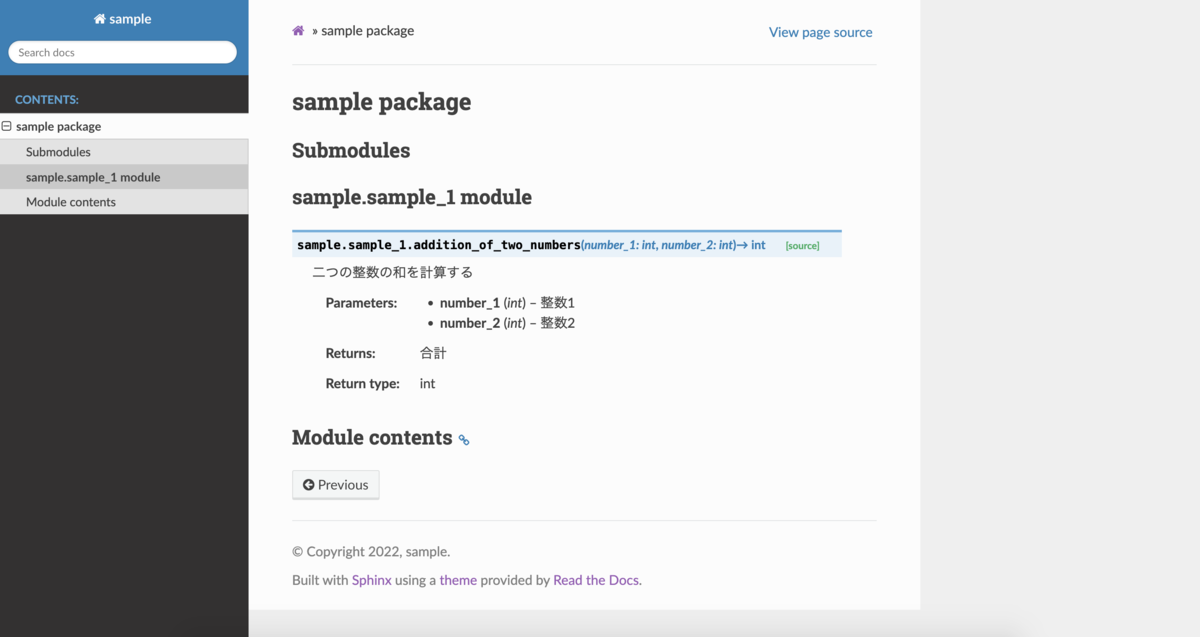
全体のソースコード
AWSTemplateFormatVersion: 2010-09-09 Description: Static contents distribution using S3 and CloudFront. Resources: # S3 バケット MyBucket: Type: AWS::S3::Bucket Properties: BucketName: "sample-bucket" # S3 バケットポリシー MyBucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: !Ref MyBucket PolicyDocument: Statement: - Action: s3:GetObject Effect: Allow Resource: !Sub arn:aws:s3:::${MyBucket}/* Principal: AWS: !Sub arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${CloudFrontOriginAccessIdentity} # CloudFront ディストリビューション CloudfrontDistribution: Type: AWS::CloudFront::Distribution Properties: DistributionConfig: Origins: - Id: S3Origin DomainName: !GetAtt MyBucket.RegionalDomainName S3OriginConfig: OriginAccessIdentity: !Sub origin-access-identity/cloudfront/${CloudFrontOriginAccessIdentity} Enabled: true DefaultRootObject: index.html Comment: !Sub ${AWS::StackName} distribution DefaultCacheBehavior: TargetOriginId: S3Origin ForwardedValues: QueryString: false ViewerProtocolPolicy: redirect-to-https # CloudFront OAI CloudFrontOriginAccessIdentity: Type: AWS::CloudFront::CloudFrontOriginAccessIdentity Properties: CloudFrontOriginAccessIdentityConfig: Comment: !Ref AWS::StackName
S3バケットの設定
- Propertiesでバケット名を指定します。
Resources: MyBucket: Type: AWS::S3::Bucket Properties: BucketName: "sample-bucket"
CloudFront ディストリビューションの設定
DistributionConfigでディストリビューションの設定をしていきます。Originsでコンテンツを配信する元となる場所(サービス)を指定します。- 今回はS3なのでそれぞれ設定します。
- Idは任意の名前を記述します。
- DomainNameでは先ほど設定した
MyBucketのRegionalDomainNameを指定します。 - S3OriginConfigのOriginAccessIdentityで次に作成するOrigin Access Identityを指定します。
- 今回はS3なのでそれぞれ設定します。
Enabledでディストリビューションを有効にするか無効にするかを指定します。DefaultRootObjectでディストリビューションのルートURLを要求したときに、CloudFrontがオリジンから要求したいオブジェクトを指定します。Commentでディストリビューションの説明を記述します。DefaultCacheBehaviorでキャッシュの動作を指定します。TargetOriginIdで先ほど指定したOriginのIdを指定します。ForwardedValuesは非推奨ですが、指定が簡単なので使用しました。QueryString: falseによってクエリ文字列が異なっても同じコンテンツとみなしてキャッシュします。
ViewerProtocolPolicyはPathPattern のパスパターンに合致する要求があった場合に、TargetOriginId で指定されたオリジンのファイルにアクセスするために視聴者が使用できるプロトコルを指定します。- 今回は
redirect-to-httpsとして「ビューアー(クライアント)がHTTPリクエストを送信すると、CloudFrontはHTTPステータスコード301(Moved Permanently)をHTTPS URLとともにビューアーに返します。- クライアントはその後、新しいURLを使用してリクエストを再送信します。
- 今回は
Resources: CloudfrontDistribution: Type: AWS::CloudFront::Distribution Properties: DistributionConfig: Origins: - Id: S3Origin # DomainName: !GetAtt MyBucket.DomainName DomainName: !GetAtt MyBucket.RegionalDomainName S3OriginConfig: OriginAccessIdentity: !Sub origin-access-identity/cloudfront/${CloudFrontOriginAccessIdentity} Enabled: true DefaultRootObject: index.html Comment: !Sub ${AWS::StackName} distribution DefaultCacheBehavior: TargetOriginId: S3Origin ForwardedValues: QueryString: false ViewerProtocolPolicy: redirect-to-https
OriginAccessIdentityの設定
- OAIというCloudFrontのユーザーを作成してCloudFrontディストリビューションに関連づけます(OAIユーザー)
- S3の対象バケットのバケットポリシーを「OAIからのみアクセスを許可する」ようにします。
Resources: CloudFrontOriginAccessIdentity: Type: AWS::CloudFront::CloudFrontOriginAccessIdentity Properties: CloudFrontOriginAccessIdentityConfig: Comment: !Ref AWS::StackName
S3バケットポリシーの設定
PropertiesのBucketで先ほど設定したバケットの論理IDを指定します。PolycyDocumentのStatementでポリシーの内容を記述します。
Resources: MyBucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: !Ref MyBucket PolicyDocument: Statement: - Action: s3:GetObject Effect: Allow Resource: !Sub arn:aws:s3:::${MyBucket}/* Principal: AWS: !Sub arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity ${CloudFrontOriginAccessIdentity}
さいごに
インフラをコードベースで管理することでインフラリソースの状態を把握できますし、今後同じ構成で何かを開発する際はインフラの構築時間を削減できると感じました。
今後も業務の中で人が行う必要がない部分は積極的に自動化して、自分を含めチームメンバーが本質的な部分に力を注げるよう行動していきたいなと思います!
株式会社フォトラクションでは一緒に働く仲間を募集しています