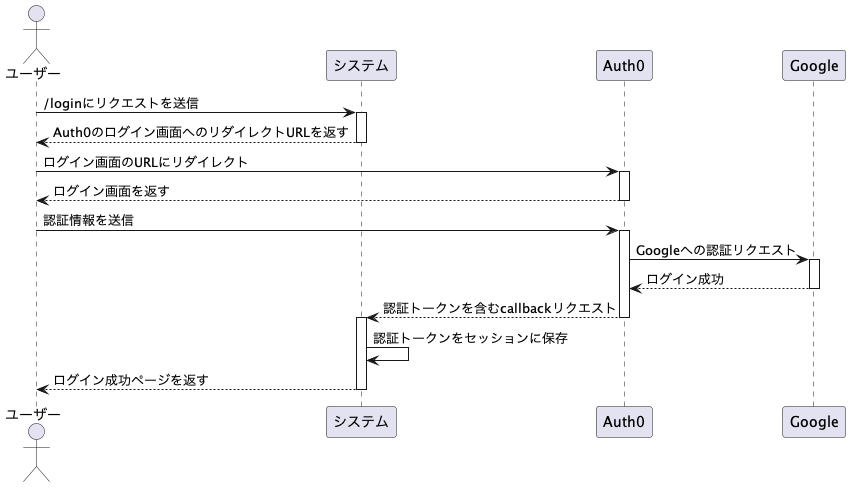
はじめまして、CREチーム所属のトヨカズです!
突然ですが、皆さんは開発組織向けの取り組みを実施していますか?
「これから実施したいけど、どんなコンテンツを考えればいいかわからない…😵」となったり「企画検討段階だけど、進め方がわからない…」だったりと企業ごとに抱えている悩みはそれぞれあるかと思います。
かくゆう弊社もそのうちの1社であり、組織力向上を図るために何をすべきか模索していました。
今回は、もがいた末に見つけた弊社なりのイベントのあり方について皆さんにお伝えできればと思います💪
photoruction Laboって何??

フォトラクションでは、社内開発イベントとして「photoruction Labo」というイベントを企画してます。
目的としてはこんな感じ↓↓↓
「3人1チームで、プロダクト作りをし、各チームメンバー同士の関係性を深めつつ、新しい技術を身につけスキルアップ向上を目的とするイベント」
いわゆるハッカソンみたいな感じです🕺
ただ、この企画他と違う点としては、長期スパン!!!
1年弱の開発を想定しています。
理由としては、あくまで新しい技術を触って欲しいという思いがあり、短期的だとどうしてもキャッチアップが難しい。また、各メンバー同士の関係性を深いものとするには、何か一つ同じ目標に向かって進んでいく時間が長い方が、関係性向上に寄与するものと考えたからです。

企画に至った背景
この企画の発端は、昨年まで続いていたAdvent Calender(通称アドカレ)に代わる別のイベントはないかと模索しているところから始まっています。
12月になると始まる、IT界隈1つの行事でもあるアドカレ。12月ってどこの部署も忙しく、正直アドカレを書いてる時間がないんですよね…けど、運営としてもやるからには強制力を働かせて書いてもらう必要もあり運営・執筆者、両者にとって負担となるイベントとなっていました💦
何とかやり切ったイベントも、みんなでやりきった感がなくては、達成感はあれど充実感はありません。この経験を元に、「もっとみんなが参加したくなる、楽しい雰囲気で進められるようなイベントを開催したいよね」という事になり、発案されたのがphotoruction Laboです✨
photoruction Laboの目的って…
企画を本格的に進めていくにあたり、目的を明確にしようという事になりました。
この企画は、アドカレの運営メンバーのまま、中村CTO、CREリーダー田中、CREメンバーの豊田(トヨカズ)で、運営を行っているのですが、企画検討段階の時に、様々な議論を行いました。
その中で、以下のような課題が見えてきました。
また、中村個人の想いとして、このイベントを通じて、個人のキャリアに広い選択肢を与えたいという想いもあり、この企画はグループでの技術開発イベントとして方針が決まりました。
やりたいことや課題に対する目的が見えてきたところで、次は企画の施策について考えていきます。以下は、イベントを企画する際に、実際に考えた内容です。
- イベントの目的に対する目標設定
- イベントのコンセプト
- スローガン決め
- スケジュール見積もり
- どんなプロダクト作りをしてもらうか
- photoruction Laboデザイン決め
こんな感じで、具体的にどういうイベントにするかを一つ一つ決めていきました!実際に決めた内容がこちら💁♀️
 企画についての概要
企画についての概要
イベントを開催するのに、大事な事!!!
イベント運営において大事な事は2つ。
- イベントを楽しむ
- 協力してくれる仲間を作る
1. イベントを楽しむ
まず、イベントを開催する上で、大事な事がイベントを企画してる人が楽しむという事だと思います。
何かをやろうという時に、惰性でやっても良いものは生まれませんし、真面目なイベントは、雰囲気も堅苦しくなるので、参加しても楽しくなかったりします。
運営が楽しそうに作ってる企画は、アウトプットも楽しいものになっているはずです。それが、参加者にとって楽しそうに見えないのであれば、ヒアリングして、楽しそうなものに作り変えていけば良いと思います。
ワクワクするもの、胸が躍るものであれば、自ずと参加したくなると思います。
僕らも企画を発表した時は、「人が集まるだろうか…」と考えたりしてましたが、結果的に9人参加してくれました👏
これから先も、越えねばならない山がたくさんありますが、失敗も成功も、道中楽しみながら歩んでいければと思います。
2. 協力してくれる仲間を作る
「いざ、企画を作りました!」となっても、この企画にGoを出す人がいないと何も始まりません。あくまで、組織としてイベントを実施するため、上の偉い人に許可を取る必要があるのです。
そこで、大事な事は「協力してくれる仲間を作る」事です。
幸い、弊社に関してはアドカレの段階から、CTOとCREリーダーと一緒に運営してたこともあり、その辺はすでにクリアしていましたが、実際に始めるとなると、1人からになる事が多いと思います。
この場合、ただひたすら運営に協力してくれそうな人を探すしかありません。とりあえず、企画書の草案くらいを片手に、自分の熱量を伝える事をしてると自然とそれに協力してくれる人が現れるはずです。
以上の2つが大事な事でしたが、兎にも角にもパワーをかけてイベントを進めようとする人がいないとイベントは始まりません。そして、イベントを練るのにしっかり時間を取る事をお勧めします。
この企画も実際に、動き出すまでに2~3ヶ月かかっています💦それくらいに、前準備に時間がかかりました。※本業がある中で、この企画に充てられる時間として週1のMTGだけだったので、進捗としては上記の感じでした。
🚧企画でつまずいたポイント
コンテンツイメージの共有
イベントを考える上で、必要になってくるのが、どんなコンテンツにするかということ。
目的は既に見えていたので、とりあえずチーム間での開発と今後の成長、キャリアの選択肢を増やすことを考慮して、運営で壁打ちしながらイメージの具体化を進めていきました。
特に、イベントが開催されたと仮定した時のチームの雰囲気、イベントの雰囲気などは、運営側でイメージの共有ができていないと、足りない部分が出てきたりするので、限りなく具体化することを意識していました。
参加者が参加したいと思えるコンテンツにするには
第一にコンテンツを評価するのは、参加者であるということ。参加するのも、参加者であるということ。そして、イベントに強制的に参加させるのではなく、自発的に意思決定を行い参加してもらうこれがいちばんのポイントだと思います。なので、この企画は、強制ではなく、有志での参加になっています。
またコンテンツについてお話をすると、運営が思う「面白い」と参加者が思う「面白い」の差異を可能な限り無くすことも重要になります。
もちろん全ての意見を取り入れることは難しかったりもするので、そこはバランスを見ての判断になると思います。
試行錯誤した結果、プロダクト例をいくつか提案して、その中から選んでもらう、またはそれ以外のことをやるでもOKという形で、会社でできる範囲の例を挙げることで、選択の幅を持たせ、自発的に選んでもらおうということになりました。
実際に挙げた例がこんな感じ↓↓↓
💡 Web/モバイル
💡 VR
- VRを利用して、フォトラクションの機能を触れるプロダクト作成
※アイディアについては、条件などなし
参加者をどうやって巻き込んでいったか
イベントを開催する前から、文面じゃ伝えきれない部分を会った時に「今度、こういうイベントやるんですけど〜🥺」みたいな感じで、宣伝をしました。
「どんなイベントだったら、参加したいと思いますか?」みたいな相談ベースで、ヒアリングを行いその際、参加してくれそうな人にも声をかけていきます。(遠方に住んでる方は、DMでも聞いたり)
また企画告知によって、認知を広めることも必要だと思っていたので、以下のように社内の至る所で、発信するようにしていました。
こういう1つ1つの行動を参加する人は無意識的にも見ていたりすると思うので、企画の本気度を伝える上でも重要だと思います。

まとめ
弊社でも、まだ走り始めたばかりで今後どうなるかわかりませんが、組織を盛り上げるためにもこういう施策は必要だと思います。チームビルディングに対するアプローチを別の角度からするのもありだと思うので、ぜひ参考にしてみてください✨